云端運維面世至今一年半,企業用戶數已突破1400家
云運維上線一年半,企業用戶已突破1400家。 為了更好的協助客戶實現系統穩定高效的使用,我們對云運維報表的布局和功能進行了優化升級。 本次更新主要有以下三個亮點:
1.報表模塊化分頁展示
2. 新的 BI 報表
3.內存負載評分功能上線
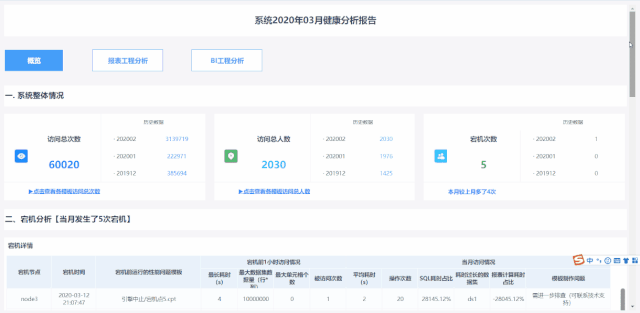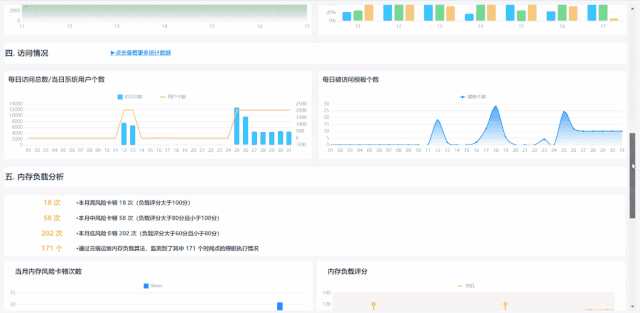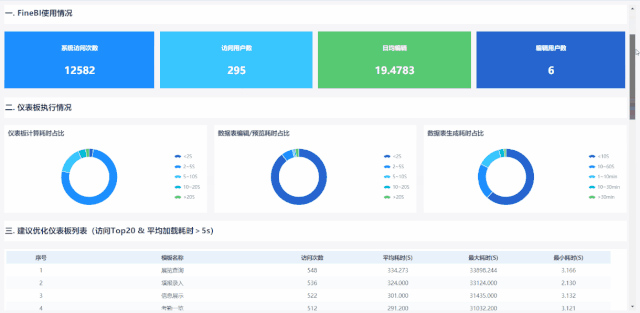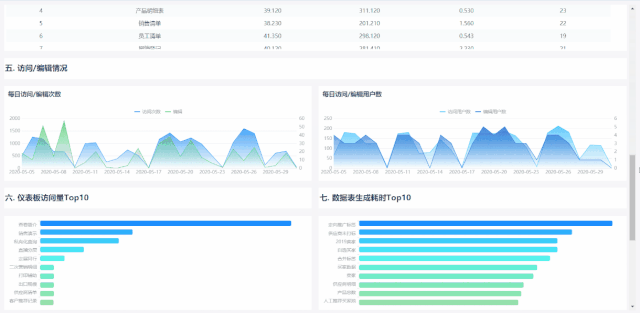
1 內容豐富分頁展示,條理更清晰
隨著云運維功能的不斷縮減,報表內容越來越豐富多彩,讓數據分析更加全面,但也帶來了結構不清晰、關鍵數據難以查找等問題。
熟悉云運維的用戶都知道,云運維的目的還是為了系統的穩定和高效,所以要達到這樣的效果,雖然分為兩個層面來重點優化:

1.服務器級別-穩定
指的是我們使用的服務器(硬件服務器或者云服務器)和支持應用運行的服務器容器(比如,等等)。那些是保證我們的應用能夠支持用戶的基礎,所以從角度運維方面,我們需要關注以下兩個方向的數據
服務器運行方向:訪問狀態(次數、人數)、內存峰值、CPU使用率峰值、輔助系統管理的一些數據(化機內存、jdk版本、操作系統、處理器架構等)
用戶體驗方向:宕機、卡頓
服務器級別的數據是整個報表的第一頁(概覽)。 說白了就是可以反映出我們的系統是否能夠正常流暢的使用。
2、應用層面——高效
是指安裝部署在服務器上的具體應用項目(如報表項目、BI項目),是系統用戶直接與系統交互,進行數據錄入/采集/分析/價值挖掘等操作的窗口,所以從運維的角度,我們需要關注以下兩個方向的數據
使用效率方向:各統計單元的延時狀態(模板/儀表盤、數據連接、數據集等)
使用頻率方向:模板訪問量(次數/人數)、日訪問量/趨勢
應用層面的數據是整個報表的第二頁和第三頁(報表工程分析、BI工程分析),分別從系統可用性的理論指標和實際數據來判斷。
結合以上兩個層面下的所有方向,在保證系統正常穩定使用的基礎上,進一步考慮系統用的多,用的好不好,讓系統真正穩定高效.
2 全新BI報表,運維分析更專業
由于兩款產品的定位不同,運維層面的數據雖然很多,但很難統一判斷和分析。 如果想對系統使用情況有更準確的控制,可以根據兩款產品的不同特點進行精細化分析。 方為上策。
雖然云從今年開始就有了這個想法,但在明年上半年持續的用戶考察和功能反饋中,貴方對BI云運維報表的需求也驗證了這個方向的正確性和必要性。 現在跟著云運維報表的BI云運維報表整體布局終于和大家見面啦~
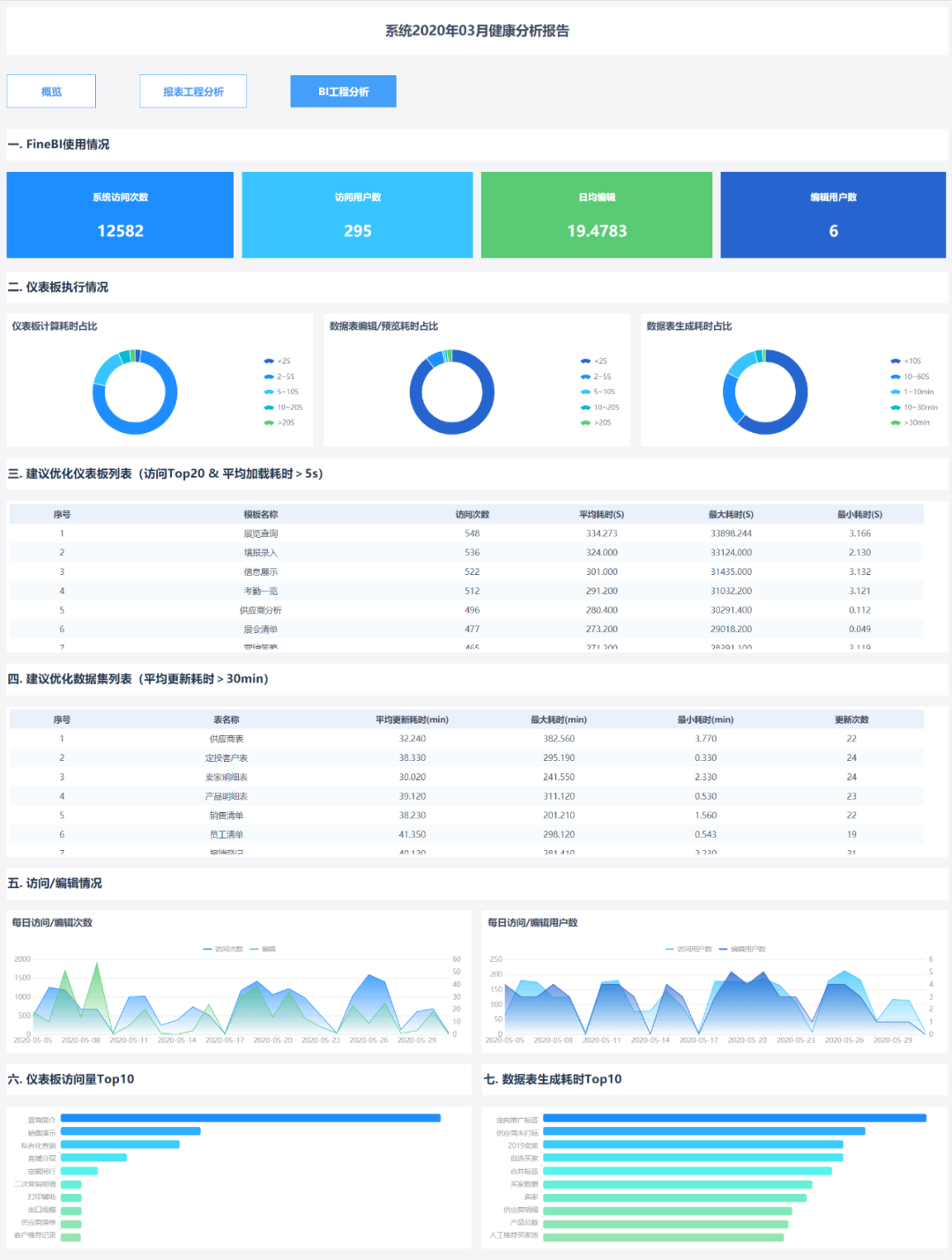
1、判斷用多了好不好的方法
報表工程更適合中國式的復雜報表。 在企業中,信息部門/IT部門的專業人員往往會在收集業務人員的需求后開發報表。
判斷這種報表用的多不多,更看重的是業務人員訪問報表的頻率和人數
判斷用的好不好,更多的是關注業務人員在訪問那些報表時所需要的各個環節的時長(SQL時長,報表預估時長等)的后臺展示
作為一款簡單易用的自助式大數據分析工具,在應用上,有別于IT連接需求的開放報表模式。 定位為業務用戶或數據分析師,根據數據需求做探索性分析,判斷這個儀表盤的性能。 Usage,在訪問維度的基礎上,我們額外縮減了編輯情況的觀察維度,包括三類數據:編輯用戶數、平均每日編輯次數、編輯時長。
從編輯的用戶數中,我們不僅可以直觀的看到用于分析的用戶總數和每日用戶數的變化,還可以分析企業自助分析模式和業務用戶數據的實現水平更深層次的分析能力。 企業的實力,企業內具有數據分析能力的人才儲備等。

從日均編輯次數可以得到業務用戶用于數據分析的平均日編輯次數,相當于在自助分析模式下為業務用戶解決了每日臨時分析問題的次數。 結合編輯儀表盤/數據集的時長,綜合對比使用excel進行分析或IT幫助業務開發報表模式,從而驗證自助分析模式對企業的價值,是否達到了以下效果:降低成本,提高效率。
分析實例:西洋雙陸棋過去只有一個IT部門為每個業務部門處理數據,現在通過BI平臺,將分析應用數據的部門擴大到近10個,擁有30+編輯用戶,培養潛力企業數據分析人才,業務部門模板平均每月編輯300次以上,平均每晚編輯10次以上,意味著業務每晚自行解決10個以上的眼前問題。
另外,從訪問的角度,包括訪問用戶數和訪問次數,可以估算每個用戶對模板的平均訪問次數,這不僅可以反映用戶對數據分析結果的依賴程度,而且也體現了自助分析下的業務。 用戶自己開發的模板的價值,即平均訪問次數越高,表明用戶對數據分析結果的依賴程度越高,單個模板的分析價值越高,依賴的可能性就越大根據數據做出決策。

2、用的多不多,好不好的統計細度
對于直接用戶,在整個使用過程中只接觸到(cpt或frm),不需要其他任何東西。 所以這部分用戶體驗的重點是問題模板,訪問頻率高,時間長的模板是運維人員優化的重點。
但是對于用戶來說,理清了數據和關系之后,使用過程涉及到的不僅僅是儀表盤,還有數據集的制作(尤其是自助數據集),所以關注的范圍不僅僅是問題儀表盤,而是還有問題數據集,經常能及時發現一些由于誤操作(比如在兩個大數據規模之間合并合并)導致的問題數據集,并進行優化,對性能的提升可能不亞于甚至超過問題儀表盤的提升。
3內存負載評分,詳細分析每次卡頓
卡頓表現為在感知比較顯著的時候系統沒有反應,無法交互。 一般一段時間后可以手動恢復正常。 但是頻繁卡頓會給用戶帶來很差的體驗,所以卡頓問題應該解決。 同樣關注系統停機時間。
1、為什么不關注卡頓?
數量多,人力少,系統掛起時間長
如今,我們通常會遇到停機問題。 比較有效的方法是在重啟前導入系統的dump文件分析定位。 理論上也可以應用于凍結問題的處理。 但是相對于宕機,卡頓的頻率要高很多,系統運維人員沒有足夠的精力對所有卡頓做如此詳細的排查。 退一步說服務器運維,我們不缺錢,所以需要招更多的人來看,所以還是有一個問題——dump 期間系統不可用服務器運維,即使人手跟得上,影響系統不可用性的影響超過了滯后的影響得不償失。
支持深度分析的數據很少
遇到卡住的問題,你的第一反應是什么? “網絡不好”絕對是最佳答案。
不排除確實有一定比例的情況是因為網絡環境的影響導致后端加載卡住,但是顯然這樣一個非人為可控的原因會隱藏很多問題,而網絡有太多的責備。 那為什么傳統的卡頓分析還停留在網絡環境、前端加載等淺層分析上呢? 由于缺乏數據支持深入分析,問題又回到了之前導入dump的矛盾。
卡頓體驗標準不統一
上面說的“卡頓表現是在感知比較顯著的時候系統沒有響應,無法交互”,雖然這個定義也有點模糊,但是“感知比較顯著”的感知成分比較多. 同樣的接入需求,新入職的小白可能認為加載20秒內可以接受,但公司領導可能等了10多秒才想和信息部談。 再加上系統的硬件條件不同……干擾原因太多,導致系統操作人員難以準確判斷很多卡頓的嚴重程度,而優先級的缺失讓高效處理變得更加困難。
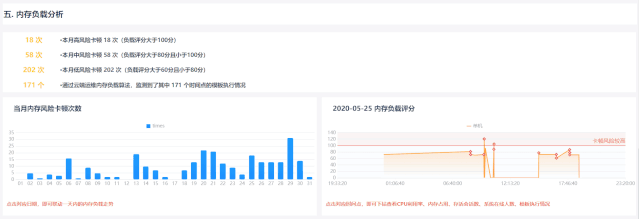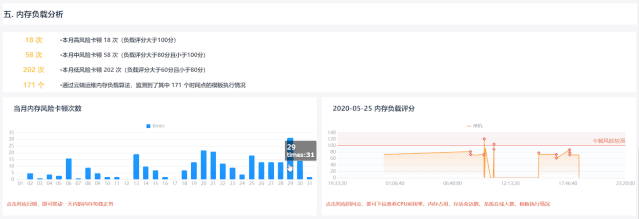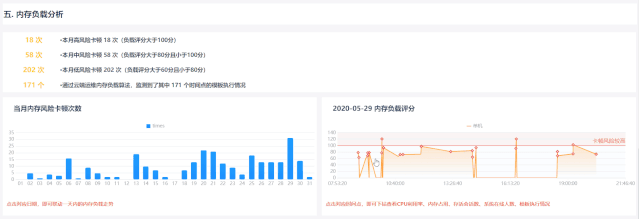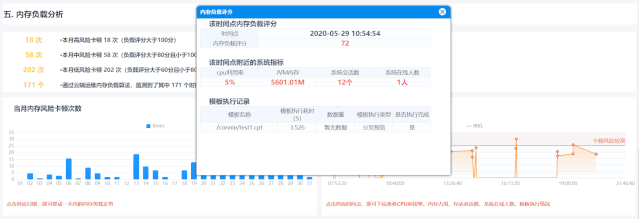
2.如何通過內存負載評分解決以上問題
分析過程完全手動且免費
依托于云運維強大的數據分析處理能力,顯存的復雜評分功能是根據GC日志手動關聯模板的執行狀態。 全程云端運維分析,無需人工輸入,不影響系統正常使用
豐富的數據支持深度分析
以當前系統顯存使用情況,輔以推廣數據,綜合考察系統顯存負載,但jvm顯存、cpu使用率、存活會話數、系統在線用戶數、加載模板等。鏈接起來,為后續分析優化提供方向
求“同”存“異”,力求判斷準確
在同一個報表系統中,使用該時間點的各個系統參數對卡點進行打分,防止人為激勵影響判斷的準確性; 不同系統根據自身硬件配置和實時顯存情況確定評分標準,具體系統具體分析,避免系統差異。 判斷無聊和不合理的標準
比如目前主流的軟件——小到補報、查詢、部署、集成,大到可視化大屏、駕駛艙,功能強大。 最重要的是,得益于這個工具,整個公司的數據結構可以出現標準化,下一步就是為企業建立一個大數據平臺。 而且,它是用java編寫的,支持二次開發,是一個類Excel的設計器。 無論是IT還是業務,都非常容易上手:編輯sql優化、數據集復用簡直就是小case,大大提高了報表開發的門檻。 . 在企業最關心的數據安全方面,支持多人同時開發同一套報表,通過模板鎖定功能避免編輯沖突; 通過數據分析和權限控制,保證數據安全。


 售前咨詢專員
售前咨詢專員
